你有没有想过—— 未来训练一个大模型,可能不再需要耗电如“小电站”的GPU集群? 处理一笔复杂的跨国金融结算,可能不需要数小时的服务器运算? 甚至做一次MRI扫描,时间能从30分钟缩短到几分钟?
这一切,正被一项刚刚登上《自然》杂志的研究悄然实现。
由微软研究院、剑桥大学与巴克莱银行联合团队开发的模拟光学计算机(Analog Optical Computer, AOC),首次实现同一硬件平台高效运行AI推理与组合优化两大任务,在理论能效上比当前最强GPU高出100倍以上。
这不是PPT概念,而是实打实的物理原型机,已通过MNIST图像分类、医学影像重建、金融交易结算等真实场景验证。
为什么我们需要一台“非数字”的计算机?
今天的人工智能,几乎全靠“数字芯片”驱动。但问题来了:
- 内存墙:数据在CPU/GPU和显存间来回搬运,消耗了超过80%的能耗。
- 功耗爆炸:训练GPT-4级别的模型,一次电费可达数万美元。
- 算力瓶颈:摩尔定律逼近极限,传统芯片再难靠“堆晶体管”提升效率。
于是,科学家们开始“回归模拟”——模拟计算不把数据变成0和1,而是用连续的电压/光强直接表达信息,天然适合矩阵乘法、迭代求解这类AI和优化核心操作。
但过去的问题是:
- 光学擅长并行乘法,但不会做tanh激活函数;
- 模拟电路擅长非线性,但没法高速传输海量数据;
- 两者结合时,必须经过昂贵的“数模转换”,吃掉大部分节能优势。
AOC的颠覆性突破,就在于彻底消除了这个“转换环节”。
AOC是如何工作的?光与电的“永动舞”
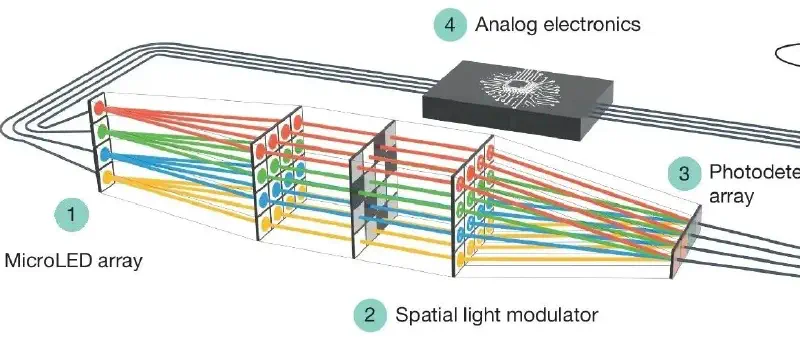
想象一个闭环系统,每20纳秒完成一次“思考”:
| 组件 | 功能 |
|---|---|
| 微LED阵列 | 将输入变量编码为光强(比如:图像像素、交易金额) |
| 空间光调制器(SLM) | 存储权重矩阵,像“光的乘法表”一样,让光信号自动完成并行矩阵乘法 |
| 光电探测器 | 将光信号转为电压,送入模拟电路 |
| 模拟电子电路 | 执行tanh非线性、减法、退火、动量更新 —— 完全在连续域中进行 |
整个过程没有ADC/DAC,没有中间缓存,所有计算都在“模拟态”中循环迭代,直到系统稳定在一个“固定点”——这正是深度平衡模型(DEQ)和优化问题的数学本质!
关键优势:
- 抗噪:固定点像引力中心,噪声越扰,越被拉回正确解
- 无内存墙:无需存储中间层激活值
- 动态深度:推理时间由收敛速度决定,不是预设层数
真实场景验证:它到底能干什么?
论文用四大案例证明AOC不是“玩具”:
- AI推理:图像分类 & 非线性回归
- 在MNIST和Fashion-MNIST上,准确率达95%–98%
- 成功拟合高斯、正弦曲线,误差低至0.00375(MSE)
- 全部训练在数字孪生模型(AOC-DT)中完成,部署到硬件无需重新校准
关键:它跑的是深度平衡模型(DEQ),一种“无限深”的递归网络,传统数字芯片跑得慢、耗电高,而AOC天生匹配。
- 医疗:MRI加速重建
传统MRI需采集大量数据才能成像,耗时长。
AOC采用L0范数压缩感知(理论上最优但极难计算),仅用62.5%的数据,就重建出接近原图的清晰脑部切片,误差降低近10倍!
- 金融:解决NP难的交易结算
全球每日有数万亿美元交易待清算,如何最大化“一次性结清”的交易数?这是典型的NP难问题。
AOC将问题建模为混合二次无约束优化(QUMO),支持二进制 + 连续变量(如:是否结算、结算金额),在7步内找到全局最优解,全程模拟运算,无任何数字后处理。
对比:量子计算机在类似问题上成功率仅40–60%,而AOC达到100%。
性能有多强?别被“百倍”吓到,我们说清楚
| 指标 | 当前原型 | 理论预测(扩展后) |
|---|---|---|
| 权重数量 | 4,096(通过时间复用实现) | 0.1亿 – 20亿 |
| 单次迭代 | 180纳秒 | 同样 |
| 能效 | 原型功耗高(驱动电路为主) | 500 TOPS/W(8位精度) |
| 对比GPU | H100约4.5 TOPS/W | 理论能效超百倍 |
重要澄清: “百倍能效”是理论推演值,基于未来模块化扩展架构; 当前原型是桌面级设备(16×16变量),用于验证原理; 真正价值不在“快”,而在“省” —— 一旦规模化,每瓦特算力将远超硅基芯片。
未来之路:十亿权重,不是梦
AOC的可扩展性设计非常聪明:
每个模块:微LED + SLM + 光电探测器 + 模拟电路 → 尺寸仅约4 cm³ 利用三维光学结构,实现光路高效复用(非平面光计算) 使用成熟消费级技术(手机里也有微LED、SLM) 多模块并联,即可扩展至百亿级权重
专家判断:若成功量产,将成为继GPU之后,下一代AI算力的核心候选架构之一。
为什么这是一场“范式革命”?
我们过去追求的是:“更快的数字芯片”。
而AOC告诉我们:
“更聪明的物理系统”才是未来。
它不是在“模仿人脑”,而是在用光和电的物理规律,直接求解数学问题。 它不依赖冯·诺依曼架构,不被内存墙束缚,不因数模转换浪费能源。
这就像从“手写算盘”进化到“机械计算器”——不是更快地拨珠子,而是换了一套计算逻辑。
结语:实验室的光,终将照亮现实
AOC目前仍是原型,距离商用还有工程挑战:热管理、三维集成、大规模制造…… 但它首次证明了:
一类硬件,可同时服务AI与优化; 模拟+光学,能超越数字芯片的能效天花板; 算法与硬件协同设计,能带来数量级突破。
当我们在为大模型的电费发愁,为自动驾驶的算力焦虑时,微软与剑桥的这支团队,已经点亮了一条通往“绿色AI”的新路径。
这不是“下一个十年”, 而是正在发生的,下一场计算革命的序章。
论文原文:(https://doi.org/10.1038/s41586-025-09430-z)
本文初稿使用AI协助编写,虽经人工校对,水平有限,请谅解。