这篇文章,主要是介绍如何在 n8n 上建立一个" 第二大脑" 的工作流,内容比较枯燥,如果想立即尝试,见文章最后的📎
这篇文章,主要是介绍如何在 n8n 上建立一个" 第二大脑" 的工作流,内容比较枯燥,如果想立即尝试,见文章最后的📎 配套资源 ,获取一键导入的 n8n 配置文件。在导入之前,确保 n8n、ollama 和 Qwen 都正常运行,相关安装方法,见网上教程。
引言:我们为什么需要“第二大脑”?
在通信行业,每一份战略规划都承载着对未来的判断。它不仅要基于历史经验、试点反馈,更要精准对齐高层意图,并洞察竞争格局。
然而,信息散落在 OA、本地磁盘、会议纪要中,专家常常陷入“找资料比写方案还累”的困境。
而我们在上篇提出的解决方案是:打造一个能“ 感知任务、融合知识、生成框架 ”的“战略型第二大脑”。
现在,是时候兑现承诺了。
本文将带您 从零开始,用开源工具本地搭建一个可用的“第二大脑” 。
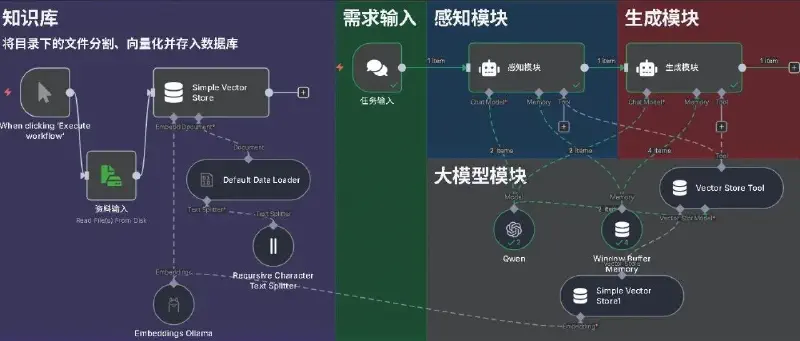
一个基于 n8n + Ollama + Qwen 的智能系统,流程如下图:
战略生成流程知识库模块读取目录文件切分文本Ollama 向量化存入 Simple Vector Store任务输入感知模块融合模块查询 Vector Store Tool生成模块输出初稿专家介入
- • 知识库模块 :构建企业“战略记忆中枢”,将散落的文档转化为可检索、可追溯、可进化的智能资产。
- • 感知模块 :听懂任务背后的“弦外之音”,解析出关键词与战略意图。
- • 融合模块 :激活企业“沉睡的知识资产”,实现跨文档、跨时间的语义关联。
- • 生成模块 :基于上下文,自动生成逻辑清晰、结构完整的方案初稿。
- • 专家介入 :最终决策与洞见注入,人机协同产出真正有价值的方案。
这套系统能否成功,80% 取决于知识库的质量,20% 取决于技术实现的合理性。接下来,我们就来一步步构建它。
步骤 1:打造可进化的“战略知识库”
🎯 目标:将分散的
.txt文件自动转化为结构化、可语义检索的知识资产。
1. 节点 1:读取指定目录下的所有文本文件(Read/Write File)
- • 节点名称 :
资料输入 - • 节点类型 :
n8n-nodes-base.readWriteFile - • 配置 :
{ "fileSelector": "d:\\\\second_brain_demo\\\\*", "options": { "fileExtension": ".txt" } } - • 功能 :扫描
d:\second_brain_demo\目录下所有.txt文件,支持通配符。 - • 输出 :以二进制形式返回每个文件内容。
💡 可扩展支持
.docx,但需确保 Ollama 支持解析。
2. 节点 2:文本切分(Recursive Character Text Splitter)
- • 节点名称 :
Recursive Character Text Splitter - • 配置 :
{ "chunkSize": 100, "chunkOverlap": 20 } - • 作用 :将长文本按字符递归切分为小片段,避免超出模型上下文。
- • 切分逻辑 :优先按
\n\n、\n、 、.分割。
⚠️ 注意:当前版本中,切分由该节点控制,而非
Simple Vector Store内置。
3. 节点 3:调用 Ollama 进行向量化(Embeddings Ollama)
- • 节点名称 :
Embeddings Ollama - • 配置 :
{ "model": "dengcao/bge-large-zh-v1.5:latest" } - • 功能 :调用本地 Ollama 服务,使用中文优化的
bge-large-zh模型生成向量。 - • 优势 :专为中文语义设计,在“领导讲话”“试点报告”等场景表现优异。
✅ 需提前运行:
ollama pull dengcao/bge-large-zh-v1.5
4. 节点 4:存入向量数据库(Simple Vector Store)
- • 节点名称 :
Simple Vector Store - • 配置 :
- • Mode:
insert- • Memory Key:
vector_store_key
- • Memory Key:
- • 连接 :
- • 输入文档 →
Default Data Loader- • 切分器 →
Recursive Character Text Splitter - • 嵌入模型 →
Embeddings Ollama
- • 切分器 →
✅ 数据将持久化在内存中,供后续查询使用。
✅ 知识库构建流程总结
| 节点 | 功能 |
|---|---|
资料输入 | 扫描目录,读取 .txt 文件 |
Recursive Character Text Splitter | 按设定规则切分文本 |
Embeddings Ollama | 使用 bge-large-zh 生成中文向量 |
Simple Vector Store | 存储为可检索的知识片段 |
🔄 此流程可绑定
Cron Trigger,实现 每日自动更新知识库 。
步骤 2:构建“懂战略”的 AI 生成引擎
🎯 目标:用户输入任务,AI 自动调用知识库,生成专业方案初稿。
1. 节点 1:任务输入(Chat Trigger)
- • 节点名称 :
任务输入 - • 类型 :
@n8n/n8n-nodes-langchain.chatTrigger - • 作用 :接收用户输入的任务指令,如: “请基于历史方案和试点反馈,制定县乡传输网低成本演进路径”
2. 节点 2:感知模块(AI Agent + 知识检索)
- • 节点名称 :
感知模块 - • 类型 :
@n8n/n8n-nodes-langchain.agent - • 核心配置 :
📌 使用的模型
- • 语言模型 :
Qwen Turbo(通过 API 调用) - • 嵌入模型 :
Ollama(用于检索) - • 记忆机制 :
Window Buffer Memory(保留上下文)
📌 系统提示词(System Message)
你是一名通信网络战略规划专家以及专业的任务分析助手。你的职责是分析用户的要求:{{$json.chatInput}},根据查询知识库 company_documents_tool 中的相关内容, 输出框架大纲。
请严格遵守以下规则:
1. 内容从知识库 company_documents_tool 获取
2. 输出内容只包含“需要做什么”,不得加入额外解释
3. 输出格式为 JSON,必须包含:
- "task": "一句话说明要完成的具体任务"
- "requirements": ["要求1", "要求2", ...]
📌 工具绑定
- • Vector Store Tool :
company_documents_tool,用于检索知识库
✅ 该模块将:
- • 解析用户意图
- • 自动调用知识库检索相关资料
- • 输出结构化任务框架
3. 节点 3:生成模块(AI Agent + 文档生成)
- • 节点名称 :
生成模块 - • 类型 :
@n8n/n8n-nodes-langchain.agent - • 系统提示词 :
你是一名通信网络战略规划专家。
你是一个专业的文档编写助手。你的任务是根据任务要求,仅使用知识库 company_documents_tool 提供的内容,生成最终文档。
请严格遵守以下规则:
1. 所有内容必须来自知识库,不得引入外部信息
2. 可以在知识库范围内进行归纳、整合,但不得编造
3. 如果某项信息未找到,请写“相关信息未在知识库中找到”
4. 文风:简洁、正式、专业
✅ 输入来自“感知模块”的结构化任务框架,输出完整方案初稿。
✅ 战略生成流程总结
| 节点 | 功能 |
|---|---|
任务输入 | 接收用户指令 |
感知模块 | 解析意图,调用知识库,输出任务框架 |
生成模块 | 基于框架与知识,生成专业文档 |
🔁 整个流程无需人工干预,AI 自主完成“理解 → 检索 → 生成”。
三、关键连接:模块如何协同工作?
| 连接 | 说明 |
|---|---|
资料输入 → Simple Vector Store | 触发知识入库 |
Embeddings Ollama → Simple Vector Store | 提供中文向量能力 |
Vector Store Tool ←→ 感知模块 & 生成模块 | 提供语义检索能力 |
Qwen ←→ 所有 AI Agent 节点 | 提供大模型推理能力 |
Window Buffer Memory ←→ 两个 Agent | 支持多轮对话上下文 |
✅ 所有 AI 能力通过标准接口连接,模块化、可替换、可扩展。
📁 知识库演示内容
为确保 AI 能生成高质量方案,建议知识库包含以下五个测试文件, 均由 LLM 生成:
| 文件名 | 内容重点 | 示例片段 |
|---|---|---|
白皮书摘要.txt | 战略目标、技术路径 | “2027 年实现县乡 100% 光缆覆盖” |
试点报告.txt | 成功/ 失败经验 | “FgOTN 设备成本高达 45 万元” |
领导讲话.txt | 战略偏好 | “要注重投资效益,避免重复建设” |
友商应用情况.txt | 竞争情报 | “B 运营商采用 DCI-BOX,部署效率提升” |
设备对比资料.txt | 技术依据 | “DCI-BOX 成本比 OTN 低 30%-50%” |
⚠️ 重要说明与边界
| 项目 | 说明 |
|---|---|
| Ollama 必须运行 | ollama serve 需常驻后台 |
| 嵌入模型必须加载 | ollama pull dengcao/bge-large-zh-v1.5 |
| Qwen Turbo 需 API 密钥 | 通过阿里云百炼平台获取 |
| 向量库存储在内存中 | 如需持久化,建议升级为 ChromaDB 或 FAISS |
| 必须人工审核 | ⚠️ AI 输出仅作参考,不可直接用于决策 |
实战演示:以“县乡传输网演进”为例
让我们用一个真实场景验证系统效果。
任务输入 :
请结合《XX 网络 2025-2027 年演进白皮书》和DCI-BOX以及FgOTN试点情况,研究县乡本地传输网的演进方向。重点考虑低成本、可持续性和与国家‘新基建’政策的契合度。参考近期领导在务虚会上关于‘网络精简’和‘区域均衡’的讲话精神。
感知模块调用融合模块输出 :
| |
生成模块调用融合模块输出初稿(语言模型不同,输出也不同) :
县乡本地传输网发展建设指导意见
一、总体目标
根据《XX 网络 2025-2027 年演进白皮书》的指导思想,结合DCI-BOX和FgOTN试点情况,推动县乡本地传输网的高质量发展。以低成本、可持续性为核心,确保与国家“新基建”政策的契合度,同时落实领导在务虚会上关于“网络精简”和“区域均衡”的讲话精神。
二、基本原则
低成本:优先采用成熟、经济的技术方案,降低建设和运维成本。
可持续性:注重资源的合理利用,确保网络长期稳定运行。
政策契合度:紧密结合国家“新基建”政策,推动技术与政策的深度融合。
网络精简:优化网络结构,提升效率,减少冗余。
区域均衡:实现城乡网络协调发展,缩小数字鸿沟。
三、重点任务
技术选型
推广DCI-BOX和FgOTN等先进技术,提升传输效率和灵活性。
结合试点经验,逐步推广适用于县乡地区的解决方案。
网络规划
根据区域发展需求,制定合理的网络布局,确保覆盖全面。
强化骨干网与接入网的协同,提升整体性能。
政策支持
积极争取国家“新基建”政策的支持,争取专项资金。
推动地方政策与国家政策的对接,形成合力。
管理机制
建立健全网络维护和管理机制,确保网络运行的稳定性。
加强人才培训,提升运维水平。
四、实施步骤
调研分析:深入调研县乡地区网络现状及需求,形成详细报告。
方案设计:基于调研结果,制定具体实施方案。
试点推进:选择典型区域进行试点,积累经验。
全面推广:总结试点经验,逐步推广至全县乡范围。
五、保障措施
组织保障:成立专项工作组,明确责任分工。
资金保障:多渠道筹措资金,确保项目顺利实施。
监督评估:建立监督评估机制,定期检查项目进展。
六、结语
县乡本地传输网的发展是推动乡村振兴和数字化转型的重要基础。通过科学规划、技术创新和政策支持,努力构建一个高效、经济、可持续的县乡传输网络,为实现“网络强国”目标贡献力量。
相关信息未在知识库中找到
结语:从“建力”到“用智”,通信人的 AI 新使命
在上一篇文章的结尾,我们提到:
“在下一篇中,我将分享如何利用开源工具,在本地环境中一步步搭建起这套能解码战略的智能系统。”
今天,我们兑现了这个承诺。
这套系统原型,还不能真正的实用,仅仅是一个最小的简单RAG系统 , 但让我们认识到:人工智能,不再遥远,而是每一位战略规划专家都 用得上、用得起、用得安心 的生产力工具。
它让我们:
- • 从 “信息搬运工” 转变为 “战略架构师” ;
- • 从 “被动响应” 升级为 “主动洞察” ;
- • 从 “经验驱动” 迈向 “数据+ 智能驱动” 。
更重要的是,它提醒我们: 作为通信人,我们不仅是 算力的建设者 ,更应成为 智能的应用者 。 国家推动“人工智能+”,不仅是让我们建更多的数据中心,更是鼓励我们 率先在自身业务中实践 AI 的价值 。
📎 配套资源
关注公众号,回复“ 第二大脑 ”(不是文章留言!),获取:
- • 本文对应的工作流 JSON 文件(可直接导入)
- • 5 份示例资料(.txt)
- • 示例资料默认存储在"D:\second_brain_demo" 目录下
- • 由于笔记本算力不足, 语言模型用阿里的免费 Qwen 模型,可以去申请免费 API_KEY